1. 교제
- Reinforcement Learning An Introduction Second Edition
- Source code : https://github.com/ShangtongZhang/reinforcement-learning-an-introduction

2. 필요한 Tool
- pycharm community version
- Download PyCharm: The Python IDE for data science and web development by JetBrains
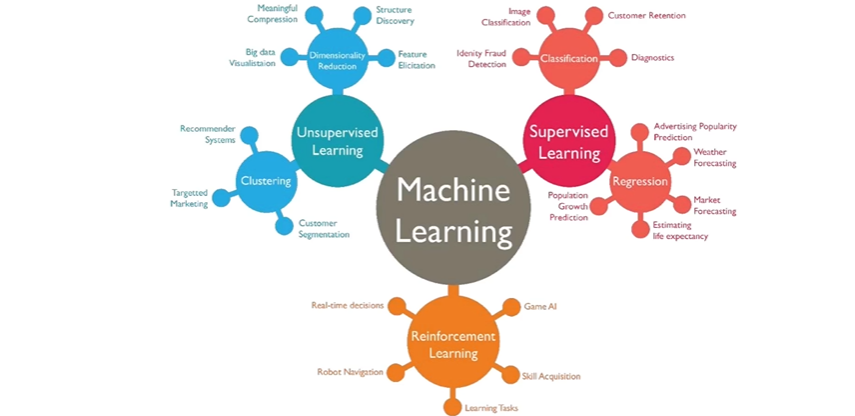
3. Machine Learning 분류
- Supervised Learning : label이 정해진 데이터를 기반으로 예측하는 기법
- Unsupervised Learning : label이 없는 데이터를 기반으로 예측하는 기법
- Reinforcement Learning : Agent가 환경과 상호작용하면서 Reward를 받아서 학습
→ 최신 동향은 세가지 기법이 혼용되어 사용되는 형태
4. Introduction to Reinforcement Learning
- 현실 세계에서의 학습이란?
- 환경과의 상호작용을 통한 학습
- 강화학습
- 강화학습은 에이전트가 환경과 상호작용하면서 최대한의 보상을 얻기 위해 행동을 학습하는 방법론
- 강화학습은 무엇을 해야할지, 즉 상황을 행동으로 매핑하는 방법을 학습하여 수치 보상을 최대화하는 것
5. 강화학습의 기본 요소 및 구조
- 에이전트(Agent) : 결정을 내리고 행동하는 주체
- 환경(Environment) : 에이전트가 상화작용하는 세계, 환경은 에이전트의 행동에 따라 변화
- 상태(State) : 에이전트가 인식하는 환경의 현재 상황
- 행동(Action) : 에이전트가 취할 수 있는 행위의 선택지
- 보상(Reward) : 에이전트가 특정 행동을 취했을 때 환경으로부터 받는 피드백 → 이 보상을 최대화하는 것이 목표
- 정책(Policy) : 상태에 따라 에이전트가 어떤 행동을 선택할지 결정하는 전략
- 가치 함수(Value Function) : 특정 상태에서 얼마나 좋은 상태인지, 혹은 특정 행동이 얼마나 좋은지를 구하는 함수

6. 탐색과 활용의 딜레마
- 강화학습의 중요하고 고유한 Challenge 중 하나는 탐험(Exploration)과 활용(Exploitation) 사이의 균형을 맞추는 것
- 탐색(Exploration) : 새로운 행동을 시도함으로써 새로운 지식을 얻는 과정
- 활용(Exploitation) : 이미 학습한 지식을 바탕으로 가장 높은 보상을 얻기 위해 행동하는 과정
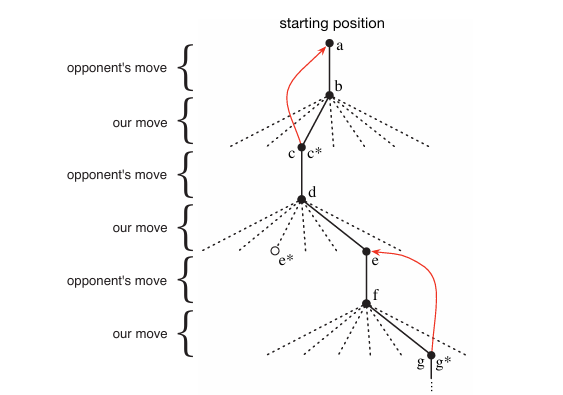
7. tic-tac-toe 게임
- 알파벳은 상태를 나타냄
- 실선은 게임 중에 실제로 한 움직임
- 별표(*)는 현재 가장 좋은 것으로 추정되는 움직임
- d에서는 e*로 가는 것이 가장 최적이나, e로 이동하는 탐색을 진행한 것
- 빨간색 선은 추정 값을 업데이트하는 과정

8. tic-tac-toe 소스
main의 경우 train, compete, play 함수로 구성
- train : reinforcement learning을 학습하는 함수
- compete : 학습된 policy를 가지고 1000번의 turn을 거치면서 이길 확률을 구함
- play : 실제 사용자와 게임을 수행
if __name__ == '__main__':
train(int(1e5))
compete(int(1e3))
play()def compete(turns):
player1 = Player(epsilon=0)
player2 = Player(epsilon=0)
judger = Judger(player1, player2)
player1.load_policy()
player2.load_policy()
player1_win = 0.0
player2_win = 0.0
for _ in range(turns):
winner = judger.play()
if winner == 1:
player1_win += 1
if winner == -1:
player2_win += 1
judger.reset()
print('%d turns, player 1 win %.02f, player 2 win %.02f' % (turns, player1_win / turns, player2_win / turns))실제 출력 값 : 1000 turns, player 1 win 0.00, player 2 win 0.00
def train(epochs, print_every_n=500):
player1 = Player(epsilon=0.01)
player2 = Player(epsilon=0.01)
judger = Judger(player1, player2)
player1_win = 0.0
player2_win = 0.0
for i in range(1, epochs + 1):
winner = judger.play(print_state=False)
if winner == 1:
player1_win += 1
if winner == -1:
player2_win += 1
if i % print_every_n == 0:
print('Epoch %d, player 1 winrate: %.02f, player 2 winrate: %.02f' % (i, player1_win / i, player2_win / i))
player1.backup()
player2.backup()
judger.reset()
player1.save_policy()
player2.save_policy()train함수 결국 backup() 함수가 핵심임
def backup(self):
states = [state.hash() for state in self.states]
for i in reversed(range(len(states) - 1)):
state = states[i]
td_error = self.greedy[i] * (
self.estimations[states[i + 1]] - self.estimations[state]
)
self.estimations[state] += self.step_size * td_errortd_error 값을 구하고, td_error에 step_size를 곱해서 현재 상태의 값을 업데이트